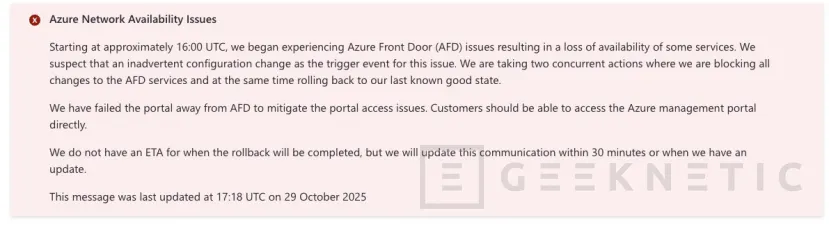
L’équipe de support Azure a signalé un problème affectant l’accès au portail Azure et les opérations de gestion associées.. La référence officielle se trouve dans le tweet publié par le compte de support et sur la page publique de statut Azure, où l’incident a été ouvert et son évolution est mise à jour.
La panne a été identifiée à 16h00 UTC, ce qui équivaut aujourd’hui à 17h00 en Espagne continentale. Cette nuance temporelle est importante car de nombreuses équipes coordonnent les fenêtres de fonctionnement et soutiennent les gardes avec les horloges locales ; Localiser le début du problème dans PST permet de reconstruire les actions tentées avant et après le point de dégradation.
Portée et impact opérationnel
Lorsque le portail tombe en panne, les services déjà déployés ne tombent pas toujours en panne, mais la gouvernance est compliquée– Affichez les ressources, faites évoluer une machine virtuelle, faites pivoter une clé, ajustez les règles du réseau ou confirmez simplement l’état d’un cluster.
En pratique, cela se traduit par des équipes qui voient leur temps de réponse allongé et dans les procédures internes qui dépendent d’une console graphique qui, parfois, ne répond pas ou répond avec une latence anormale. La page d’état Azure classe ces événements comme incidents affectant le plan de contrôle : la couche qui coordonne et gère les ressources.
Ce type de dégradation ne ralentit pas nécessairement les charges de travail en cours, mais il augmente le risque opérationnel car il gêne les actions manuelles ou automatisées déclenchées depuis la plateforme de gestion elle-même.
Ce que dit Azure et comment il le communique
Le message du support Azure est clair dans la forme et prudent sur le fond: reconnaît l’incident, indique que l’équipe travaille sur l’enquête et l’atténuation, et se réfère à la page d’état pour suivre les détails par régions et services.
Ce modèle de communication a deux vertus. La première, limiter l’anxiété : ne pas spéculer sur les causes ou les délais tant que l’ingénierie ne clôture pas les hypothèses. La seconde est de fournir une source unique faisant autorité avec des mises à jour chronologiques, afin que les équipes techniques, les chefs d’entreprise et les fournisseurs consultent la même horloge.
Comment vous sentez-vous au sein d’une équipe ?
Au-delà du titre, le véritable impact apparaît dans les processus quotidiens. Quiconque utilise une infrastructure en tant que code et des pipelines de déploiement peut voir comment certaines étapes qui appellent le plan de contrôle échouent dans une chaîne, même si les services back-end continuent d’émettre du trafic.
Qui dépend du portail pour des actions ponctuelles (examiner les métriques de dernière minute, redémarrer un service spécifique, ouvrir temporairement un port), rencontre un mur subtil: La page se charge, mais certaines opérations ne se terminent pas ; ou le « spinner » n’est pas résolu et vous devez réessayer. Dans des environnements réglementés, cette incertitude nécessite de documenter chaque tentative et de justifier pourquoi un changement urgent a été reporté, avec pour conséquence l’usure des gardes et de l’équipe de communication interne.
Que pouvez-vous faire en attendant ?
Même si l’origine est du côté du fournisseur, il existe une marge de manœuvre. L’expérience montre que le maintien d’itinéraires de gestion alternatifs réduit les temps d’arrêt. Si le portail est dégradé, Azure CLI et PowerShell offrent généralement une route plus directe vers les API ; Il convient de préparer les commandes critiques (ajout de ressources, changements de taille, redémarrages contrôlés, obtention d’états) afin de ne pas improviser sous la pression.
À quoi s’attendre ensuite
Dans ce type de situations, Azure généralement mettre à jour le calendrier avec les étapes d’enquête, d’atténuation provisoire et de récupération complèteet publie plus tard un analyse post-incident détaillant les causes et les mesures préventives.
En attendant cette clarification, la chose raisonnable à faire est de suivre le fil de discussion officiel du support Azure et la page d’état, d’enregistrer ce qui s’est passé dans votre propre runbook et, le cas échéant, d’ajuster les fenêtres de modification. L’heure de référence (début 16h00 UTC) est ainsi fixée pour tout audit ou comparaison des métriques de performances et d’erreurs.
L’incident annoncé par le Support Azure et rapporté sur la page d’état n’était pas, à notre connaissance, une baisse généralisée des charges de travail, mais plutôt une dégradation importante de la couche de gestion qui affecte les opérations quotidiennes. A partir de là, la recommandation est pragmatique: utiliser des voies administratives alternatives, limiter les changements non critiques, renforcer la communication interne et tout noter pour une analyse sereine à l’arrivée du rapport officiel. Le cloud est une infrastructure ; et l’infrastructure, en cas de panne, est gérée méthodiquement et avec une horloge bien synchronisée.